目录
- 正则表达式是什么
- 元字符
- 贪婪匹配、非贪婪匹配和独占模式
- 分组和引用
- 四种匹配模式
- 断言
- 常用正则Demo
正则表达式是什么
校验数据的有效性、查找符合要求的文本以及对文本进行切割和替换等操作。正则表达式的目的是真正的强大之处就在于可以查找符合某个规则的文本。
元字符
1.特殊字符串
- . 除换行符外任意字符
- \\d 表示任意单个数字
- \\w 表示任意单个数字或字母或下划线
- \\s 表示任意单个空白符
\\D \\W \\S,意思正相反。
2.空白符
- \\r 回车符
- \\n 换行符
- \\f 换页符
- \\t 制表符
- \\v 垂直制表符
- \\s 任意空白符
3.量词
- * 代表0次到多次
- + 1次到多次
- ? 0到1次
- {m} 出现m次
- {m,} 出现至少m次
- {m,n} m到n次
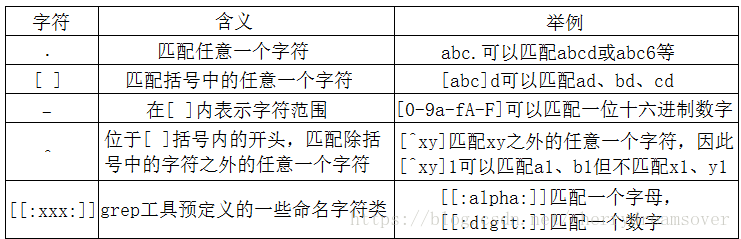
4.范围
- |或 ,如ab|bc代表ab或bc
- […] 多选一,括号中任意单个元素
- [a-z] 匹配a-z之间任意单个元素
- [^..] 取反,不能包括括号中的任意单个元素
贪婪匹配、非贪婪匹配和独占模式
- 贪婪模式的特点就是尽可能进行最大长度匹配
- 非贪婪模式会尽可能短地去匹配。
- 独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+),例如xy{1,3}+yz
注意: Python 和 Go 的标准库目前都不支持独占模式。
(“.+?”)|\\w{2,6}
分组和引用

如图所示的正则,将日期和时间都括号括起来。这个正则中一共有两个分组,日期是第 1 个,时间是第 2 个。
1.不保存子组
分组的作用就是后续可能还会被引用到,但是如果不需要引用的时候可以添加不保存子组,表达式(?:xxx),优点是正则性能会更好,在子组计数时也更不容易出错。
2.括号嵌套

四种匹配模式
1.不区分大小写模式(Case-Insensitive)
不区分大小写模式,正则表达式(?i)cat,这样匹配的字符就不区分大小写了
如果我们想要前面匹配上的结果,和第二次重复时的大小写一致,那该怎么做呢?我们只需要用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。正则表达式((?i)cat)
2.点号通配模式(Dot All)
元字符里讲.可以匹配除了换行以外的任何元素,用单行模式中使用.,正则表示式(?s).
3.多行匹配模式
多行模式的表达式(?m)^…|…$,这样的匹配好处是每一行
4.注释模式
略…
断言
断言是指对匹配到的文本位置有要求。
1.单词边界
在准确匹配单词时,我们使用 \\b…\\b 就可以实现了,也可以指定表达式的开头和结尾^…$
2.环视
环视的主要是定义清晰的边界。
- (?<=Y),左边是Y
- (?<=!Y),左边不是Y
- (?=Y),右边是Y
- (?!Y),右边不是Y
左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
常用正则Demo
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
- 匹配中文字符的正则表达式: [u4e00-u9fa5]
- 匹配双字节字符(包括汉字在内):[^x00-xff]
- 匹配空白行的正则表达式:ns*r
- 匹配HTML标记的正则表达式:<(S*?)[^>]*>.*?|<.*? />
- 匹配首尾空白字符的正则表达式:^s*|s*$
- 匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
- 匹配网址URL的正则表达式:[a-zA-z]+://[^s]*
- 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 匹配国内电话号码:d{3}-d{8}|d{4}-d{7}( 匹配形式如 0511-4405222 或 021-87888822)
- 匹配中国邮政编码:[1-9]d{5}(?!d)
- 匹配身份证:d{15}|d{18}
2.匹配特定数字:
- 匹配正整数 ^[1-9]d*$
- 匹配负整数 ^-[1-9]d*$
- 匹配整数 ^-?[1-9]d*$
- 匹配非负整数(正整数 + 0)^[1-9]d*|0$
- 匹配非正整数(负整数 + 0)^-[1-9]d*|0$
- 匹配正浮点数 ^[1-9]d*.d*|0.d*[1-9]d*$
- 匹配负浮点数 ^-([1-9]d*.d*|0.d*[1-9]d*)$
- 匹配浮点数 ^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$
- 匹配非负浮点数(正浮点数 +0) ^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$
- 匹配非正浮点数(负浮点数 + 0) ^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$
3.匹配特定字符串:
- 匹配由26个英文字母组成的字符串 ^[A-Za-z]+$
- 匹配由26个英文字母的大写组成的字符串 ^[A-Z]+$
- 匹配由26个英文字母的小写组成的字符串 ^[a-z]+$
- 匹配由数字和26个英文字母组成的字符串 ^[A-Za-z0-9]+$
- 匹配由数字、26个英文字母或者下划线组成的字符串 ^w+$
- 只能输入数字:^[0-9]*$
- 只能输入n位的数字:^d{n}$
- 只能输入至少n位数字:^d{n,}$
- 只能输入m-n位的数字:^d{m,n}$
- 只能输入零和非零开头的数字:^(0|[1-9][0-9]*)$
- 只能输入有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
- 只能输入有1-3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
- 只能输入非零的正整数:^+?[1-9][0-9]*$
- 只能输入非零的负整数:^-[1-9][0-9]*$
- 只能输入长度为3的字符:^.{3}$
- 只能输入由26个英文字母组成的字符串:^[A-Za-z]+$
- 只能输入由26个大写英文字母组成的字符串:^[A-Z]+$
- 只能输入由26个小写英文字母组成的字符串:^[a-z]+$
- 只能输入由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 只能输入由数字、26个英文字母或者下划线组成的字符串:^w+$
- 验证用户密码:^[a-zA-Z]w{5,17}$正确格式为:以字母开头,长度在6-18之间,
- 只能包含字符、数字和下划线。
- 验证是否含有^%&'',;=?"等字符:`[^%&'',;=?x22]+`
- 只能输入汉字:^[u4e00-u9fa5],{0,}$
- 验证Email地址:^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$
- 验证InternetURL:^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$
- 验证电话号码:^((d{3,4})|d{3,4}-)?d{7,8}$
以上就是正则表达式基础学习一文入门的详细内容,更多关于正则表达式基础的资料请关注悠久资源网其它相关文章!
您可能感兴趣的文章:
- python正则表达式re模块的使用示例详解
- 一文详解密码的正则表达式写法
- 正则表达式在js前端的15个使用场景梳理总结
- Kotlin语言编程Regex正则表达式实例详解
- 匹配数字小数和逗号的正则表达式