目录
- 一、正则的含义
- 二、正则表达式的应用场景
- 三、常用的格式校验
- 四、元字符
- 五、反义代码
- 六、限定符
- 七、分组匹配
- 八、贪婪与非贪婪
- 九、零宽断言
- 十、常用的实用正则表达式
一、正则的含义
正则表达式就是用来操作字符串的一种逻辑公式
二、正则表达式的应用场景
- 数据分析时数据获取的文本筛选
- 进行爬虫时,网页数据的匹配
- 写前端代码的时候,用户输入数据的验证
- 测试人员对请求结果的数据验证
- 批量文本编辑,比如Sublime Text或nodepad++、EditPlus等记事本软件全都支持正则表达式的使用
三、常用的格式校验
- 邮箱验证
- IP地址验证
- 电话号码验证
- 身份证号码验证
- 密码强度验证
- 网址验证
- 汉字验证 [\\u4e00-\\u9fa5]
- ……
- 凡是有一定规律的,批量的数据获取,都可以使用正则表达式来完成
四、元字符
五、反义代码
反义代码的意思就是与元字符表示相反的代码
- \\W 匹配的任意 不是 字母、数字、下划线、汉字 的字符
- \\S 匹配任意 不是 空白符的字符
- \\D 匹配任意 不是 数字的字符
六、限定符
七、分组匹配
- findall / search/match 区别¶
- findall 是查找所有的
- search 匹配第一个
- match 匹配开头的
八、贪婪与非贪婪
- 贪婪的意思是尽可能多的匹配
- 非贪婪的意思就是尽可能少的匹配
- 非贪婪操作符是问号:'符号?'
- ?号代表的是重复0次或者是1次,再加一个问号,代表的是非贪婪操作,那么最后就只匹配0次
分支条件匹配:
使用 | 来分隔开不同的正则表达式,代表着 条件1 或 条件2 或条件3 ……
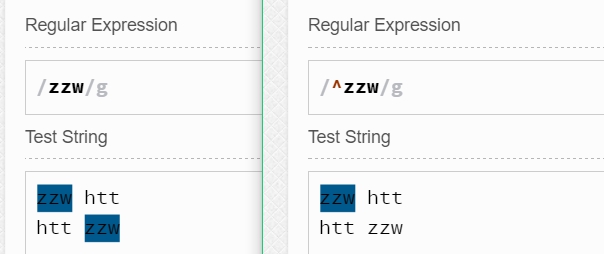
九、零宽断言
- 匹配"正则表达式reg"前边的位置 (?=reg)
- 匹配"正则表达式reg"后边的位置 (?<=reg)
- 匹配后边跟的不是"正则表达式reg"的位置 (?!reg)
- 匹配前边不是"正则表达式reg"的位置 (?<!reg)
十、常用的实用正则表达式
- 输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。
- 输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。
- 输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。
- 输入非零的正整数:"^"+?[1-9][0-9]*$"。
- 输入非零的负整数:"^"-[1-9][]0-9"*$。
- 输入长度为3的字符:"^.{3}$"。
- 输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。
- 输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。
- 输入由26个小写英文字母组成的字符串:"^[a-z]+$"。
- 输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。
- 输入由数字、26个英文字母或者下划线组成的字符串:"^"w+$"。
- 验证用户密码:"^[a-zA-Z]"w{5,17}$"正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。
- 验证是否含有^%&’,;=?$""等字符:"[^%&’,;=?$"x22]+"。
- 只能输入汉字:"^["u4e00-"u9fa5]{0,}$"
- 验证Email地址:"^"w+([-+.]"w+)*@"w+([-.]"w+)*"."w+([-.]"w+)*$"。
- 验证InternetURL:"^http://(["w-]+".)+["w-]+(/["w-./?%&=]*)?$"。
- 验证电话号码:"^("("d{3,4}-)|"d{3.4}-)?"d{7,8}$"正确格式为:"XXX-XXXXXXX"、"XXXX- XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX"。
- 验证身份证号(15位或18位数字):"^"d{15}|"d{18}$"。
- 验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"1"~"12"。
- 验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"和"1"~"31"。
到此这篇关于正则表达式详析+常用示例的文章就介绍到这了,更多相关正则表达式 内容请搜索悠久资源网以前的文章或继续浏览下面的相关文章希望大家以后多多支持悠久资源网!
您可能感兴趣的文章:
- Golang爬虫及正则表达式的实现示例
- 正则表达式用法详解
- C#正则表达式Regex类的用法
- jmeter正则表达式实例详解