3月,在GPT-4的发布之初,OpenAI就表示将在本次的迭代中加入多模态整合,即不仅仅只通过文字输入进行识别分析,还可以通过语音输入、图片输入甚至视频输入进行信息的获取、识别、分析、输出。这项功能让不少用户深深期待,毕竟文字是抽象的,是需要一定的整合能力的,而图片一拍即合,简单自然,不用费劲儿地去描绘眼前的事物。

AI生成
我也曾写过一篇文章来描述GPT4的视觉识别系统,但当时其仅在一款叫做“Be My Eyes”的应用上应用,来帮助视觉障碍朋友进行一些基础的物品识别。

【Ai时刻】是谁独享GPT-4的视觉识别系统?让Ai成为视觉障碍者的眼睛
在经历法规限制、算力紧张、AI伦理大讨论以及各新进竞争者围追堵截后,北京时间9月26日凌晨,OpenAI悄咪咪发布了其GPT-4V模型,即多模态模型,其中最引人注目的还是视频识别功能,接下来就让我们看看其工作时是什么样的吧。

原视频地址点击图片查看
视频中的用户使用官方的ChatGPT iOS客户端进行演示。首先拍摄上传了一张自行车的照片,并询问GPT,如何帮助他将车座放下来。

GPT回答让用户找到快速释放杆或螺栓,打开它们,向下滑动座椅到合适高度,然后拧紧固定。并给出了经典的AI分点回答。
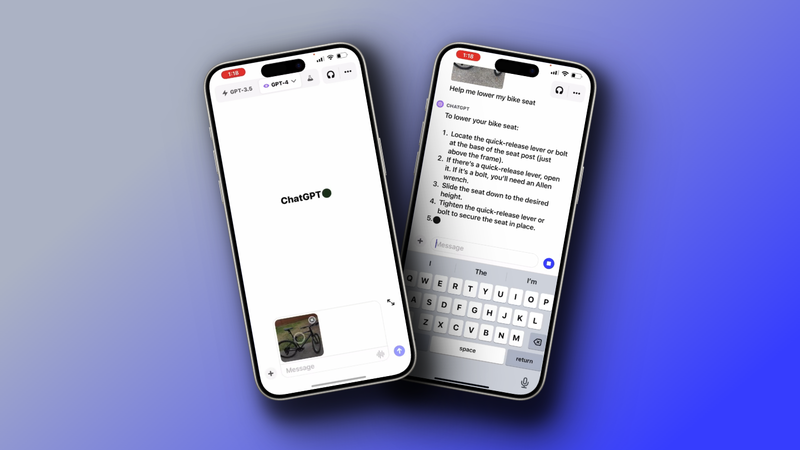
用户拍照确认了GPT所述的车座释放螺栓位置,GPT给出了肯定。


但最让我感到意外的是,其在结尾处,GPT在结尾处询问用户是否有工具,并拍照展示给它,它可以告诉用户用哪个!

用户将工具和清单拍给GPT后,GPT给出了肯定,并引导用户使用“工具箱的左边”的标记为DEWALT的4mm六角板子来松开阀座环上的螺栓并调整阀座高度。之后记得把它拧紧。

如果前面的自行车识别和车座调节识别都还是开胃菜,这一手“使用”工具真的把我嗅到了,展现出了GPT非常强大的物品识别、认知、分析能力。

今晨OpenAI还发表了一篇文章来解释、总结这一能力:OpenAI已经发布了一份详细的19页报告,关于其最新的多模态模型GPT-4V(ision),这一模型结合了其前身ChatGPT-4的语音和图像更新。该报告提供了大量关于模型开发和能力的信息。
GPT-4V是OpenAI于2022年完成训练,并计划在2023年3月开始提供早期访问的新型AI模型。GPT-4V的训练采用了与GPT-4类似的方式,先利用大规模标注数据进行无监督预训练,再通过强化学习的人机交互进行针对性调优。

AI生成
这种训练方式源自OpenAI与视障支援组织“Be My Eyes”的合作项目。OpenAI将名为“Be My AI”的视觉描述功能集成到“Be My Eyes”的手机App中,让盲人用户拍照后获得图像内容的语音描述。这种人机协作生成的多模态训练数据,极大地丰富了GPT-4V对真实场景的理解能力。

GPT-4V的图像理解能力突出,在地标识别、文字识别、人脸检测等任务上展现出较强的水平。具体来说,GPT-4V具备以下主要特征:
-物体检测 – 可以定位图像中的各类日常物体,如汽车、动物、家具等,并可以判断数量和方位
-文本识别 – 具备字符识别能力,可以检测图中的字体和手写文字,并转录成文本
-人脸识别 – 可判断脸部的位置、性别、年龄、种族等面部特征
-验证码识别 – 通过视觉推理可以破解包含文字和图片的验证码
-地理定位 – 可以分析风景图像中出现的地标建筑,判断拍摄地的具体城市或地点。

AI生成
尽管能力强大,GPT-4V在处理复杂图像时仍存在局限。它在理解图像中的空间关系、处理重叠物体、分离前景背景等方面可能不太准确,也难以捕捉细微的文本和详情。
此外,GPT-4V的决策过程不透明,结果的可解释性有限。考虑到其破解验证码的能力,OpenAI也在评估其对互联网安全的潜在影响。综上所述,GPT-4V代表了多模态AI的重要进展,同时还面临诸多挑战。OpenAI表示会积极与研究团体合作,推动GPT-4V向着更可控、可解释和负责任的方向发展。
据悉该功能将于2周以内逐渐面向用户开放,但前提是能正常使用ChatGPT App。




























