关关采集器通用替代符(适用所有关关版本)
1、内容:((.|\n)+?)
2、需要的:(.+?)
3、不需要的:.+?
4、书号:(\d+)
5、不要地址:\d*
6、分页:{Page}
1. \d* 表示数字
2. \s* 空格或换行
3. .+? 表示不需要的字符
4. .* 表示字符
5. () 表示需要截取的部分
6. ((.|\n)*) 章节内容截取
7. . 表示单个字符
8. $ 表示结束字符 例如正则表达式weasel$ 能够匹配字符串”He’s a weasel”的末尾,但是不能匹配字符串”They are a bunch of weasels.”。
9. ^ 表示一行的开始
10. < [^<]*((?<=<(?:img|IMG)[^>]*(?:(?:src|SRC)(?:\s*=\s*(?: [“‘]?))))(?:[^\s”‘>]*)\.(?:jpg|gif|jpeg|bmp|png|GIF|JPG)) [^>]*> 万能图片代码
————————————————
实例教程
第一步 1.寻找目标站 这里我们拿 笔趣阁 https://www.biquge.biz 为例子
2. 复制原有规则为采集模板 并改名为 biquge.biz.xml
3.打开关关规则编辑器 选择 biquge.biz.xml 载入
4. 开始编写规则.
第二步 1.RULEID(规则编号)这个任意写即可
2.GetSiteName(站点名称)这里我们写biquge.biz
3.GetSiteCharset(站点编码) 这里我们打开www.biquge.biz源代码查找 charset= 得到charset=gbk这个gbk就是我们需要的站点编码
4.GetSiteUrl(站点地址)目标站地址 写入http://www.biquge.biz
5.NovelSearchUrl(站点搜索地址) 这个搜索栏地址的获得,按照每个网站程序的不同,适当的修改(也可以忽略)
6. NovelListUrl(站点最新列表地址) 目标站点显示更新的网址 例如 http://www.biquge.biz
7.NovelList_GetNovelKey(从最新列表中获得小说编号)在这个规则中我们要获取小说名和小说编号 例如 这个地址查看源文件,我们编写这个规则的时候找到想要获得的内容所在的地方,比如我们打开地址看到想要获得的内容的第一本小说的名字是“从大秦开始的西游”我们在源文件里面找到“从大秦开始的西游”
<span class=”s1″>[修真小说]</span>
<span class=”s2″><a href=”/47_47923/” target=”_blank”>从大秦开始的西游</a></span>
<span class=”s3″><a href=”/47_47923/869686.html” target=”_blank”>第623章 追杀金翅大鹏,守株待兔【求订阅求月票】</a></span>
<span class=”s4″>铁木七</span><span class=”s5″>12-17</span>
以上代码中 我们要找到 <span class=”s2″><a href=”/47_47923/” target=”_blank”>从大秦开始的西游</a></span> 把这段代码 改成
<span class=”s2″><a href=”/(\d*)_(\d*)/” target=”_blank”>(.+?)</a></span> 其中 (\d*) 表示小说编号 (.+?) 表示小说名 测试下 获取正常
8.NovelUrl(小说信息页地址)这个很简单 比如 https://www.biquge.biz/47_47923/ 从大秦开始的西游 这本小说 我们可以看到的 我们改下 将里面的47改成{NovelKey/1000},47923 换成 {NovelKey} 一般情况表示小说编号 就是 https://www.biquge.biz/{NovelKey/1000}_{NovelKey}/
9.NovelErr(小说信息页错误识别标记) 这个我们随便输入一个没的小说的编号如https://www.biquge.biz/87_87923/这样我们获得的错误标记就是:对不起,该文章不存在!
10. NovelName(获得小说名称正则)我们还是打开 从大秦开始的西游 这本小说 https://www.biquge.biz/47_47923/ 查看源代码 获得小说名称 这个我们可以从固定模式着手 比如我们刚才打开的 从大秦开始的西游 这本小说 我们看到他的固定小说名格式是 从大秦开始的西游 那我们在源代码里 找到 从大秦开始的西游 这个 我们得到的内容是
<h1>从大秦开始的西游</h1> 改成 <h1>(.+?)</h1>
NovelAuthor(获 得小说作者)、LagerSort(获得小说大类)、SmallSort(获得小说大类)、NovelIntro(获得小说简介)、 NovelKeyword(获得小说主角(关键字))、NovelDegree(获得写作进程)、NovelCover(获得小说封面) 这些同 10. 一样获取即可
这里地方补充一下,有些站点头部信息完善的可以通过获取关键词这个方式 meta name=”keywords” content=”(.+?)”/> 可以用此方式获取作者,进度,封面图等信息。
11.NovelInfo_GetNovelPubKey(获得小说公众目录页地址)这个的地址获得跟上面的一样的方法
12.PubIndexUrl(公众目录页地址) 这个我说明一下,这个的用法这个一般是在知道采集目标站的动态地址的时候用到,如果不知道对方动态地址的话就在这个里面写入{NovelPubKey} 如果知道动态路径比如说https://www.biquge.biz这个站的每一本小说的章节目录都是静态地址那么 PubIndexUrl 这个的规则就是
https://www.biquge.biz/{NovelKey/1000}_{NovelKey}/
PubVolumeSplit(分割分卷)这个分割分卷 按照目前排名比较靠前的站点来说都已经取消了分卷阅读的功能,此处可以忽略
14.PubVolumeName(获得分卷名) 想要获得准确的分卷名,必须在上面的分割部分的正则必须正确,一般情况下分割部分跟分卷名是在一块的
按照目前排名比较靠前的站点来说都已经取消了分卷阅读的功能,此处可以忽略
15. PubChapterName(获得章节名) 这个我们拿一段来说明<dd><a href=”/47_47923/569996.html” >第1章 阴阳生死卷【求收藏求推荐票】</a></dd>
如果有碰到时间、日期、更新字数什么的我们直接忽略,因为这些不是我们要获得的内容,这个我们可以用 .+? 来表示。 好了我们吧上面的那一段改下改成表达式
<dd><a href=”/\d*_\d*/\d*.html”>(.+?)</a></dd>
不是单行的话我们用\s* 来表示N个换行符
16.PubChapter_GetChapterKey(获得章节地址(章节编号))这里说明下 这个里面的章节编号是在下面的 PubContentUrl(章节内容页地址)用到,那么这里我们需要获得的是章节地址分析得到
<dd><a href=”/\d*_\d*/(\d*).html”>.+?</a></dd>
章节地址那为什么我们还有用到章节名的呢?这个说下主要就是为了避免获得的章节名跟获得的章节地址不匹配。
如果是章节页是乱序的这里就要获得章节编号了(强烈见意用户用获得章节编号)
我们说下章节编号的写法 其实并不麻烦只需要稍微改下就行了。
<dd><a href=”/\d*_\d*/(\d*).html” >.+?</a></dd>改成这样就可以了
17. PubContentUrl(章节内容页地址) 这里我拿 https://www.biquge.biz/47_47923/569996.html 这个来说明下该怎么用,其中的47923这个是小说编号这里我们用{NovelKey} 替代,569996这个就是在 PubChapter_GetChapterKey 里面获得的 章节编号我们{ChapterKey} 替代,以后我们分两种写法说明
https://www.biquge.biz/{NovelKey/1000}_{NovelKey}/{ChapterKey}.html
注: 这种写法 PubChapter_GetChapterKey里必需是获得章节编号的如 “<dd><a href=”/\d*_\d*/(\d*).html” >.+?</a></dd>”
或者直接用
{ChapterKey}
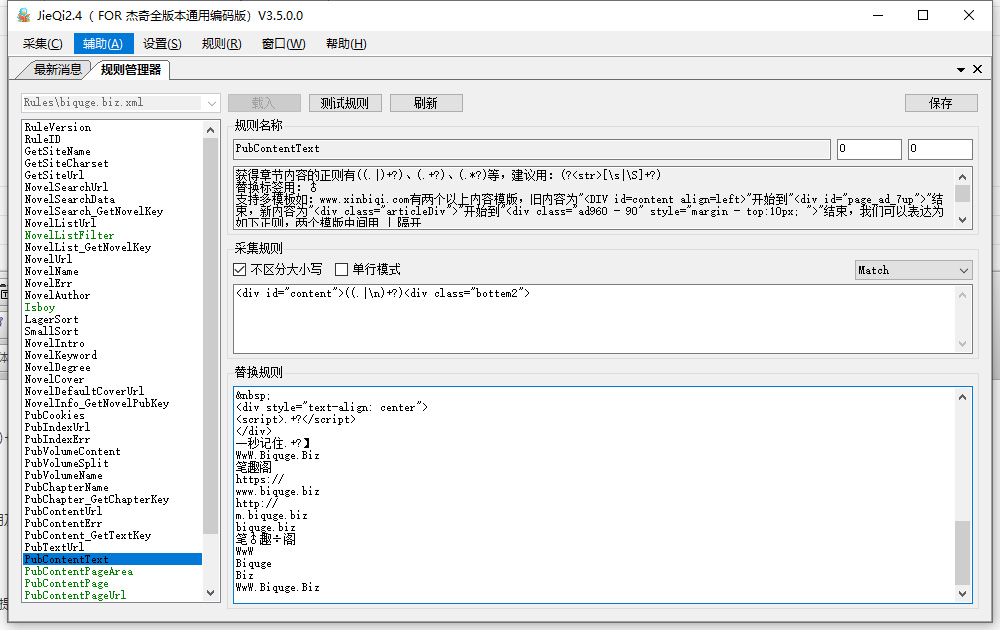
18. PubContentText(获得章节内容) 这个获得方法我们就拿 https://www.biquge.biz/47_47923/569996.html 这个地址来说吧,打开源代码我们看到
<div style=”text-align: center”><script>read2();</script></div>
<div id=”content”>
……………. ……………. 中间省了………… ……………. ……………..
<div style=”text-align: center”><script>read3();</script></div>
<div class=”bottem2″>
直接改成 <div id=”content”>((.|\n)+?)<div class=”bottem2″>
((.|\n)+?)为我们要获取的内容,
这里需要匹配过滤规则,把所有无用及广告字节进行过滤
19.PubContentImages(章节内容中提取图片正则) 章节中图片可以直接用我们上面提到的万能图片规则
<[^<]*((?<=<(?:img|IMG)[^>]*(?:(?:src|SRC)(?:\s*=\s*(?:[“‘]?))))(?:[^\s”‘>]*)\.(?:jpg|gif|jpeg|bmp|png|GIF|JPG))[^>]*>
20.出现空章节情况有可能是目标站正好重启网站或者你的采集IP被封等原因
如 果不是以上原因,请先检查你采集的章节是否是图片章节,如果你的PubContentImages(章节内容中提取图片) 没有获得图片章节内容的话软件 就会检查你的采集文字内容 PubContentText(获得章节内容)这个里面的正则的匹配,如果 PubContentImages(章节内容中提 取图片) 跟PubContentText(获得章节内容) 都没有匹配的内容,那么就出现了上面我们说的空章节的原因。
最后保存规则后重新载入规则进行“测试规则”
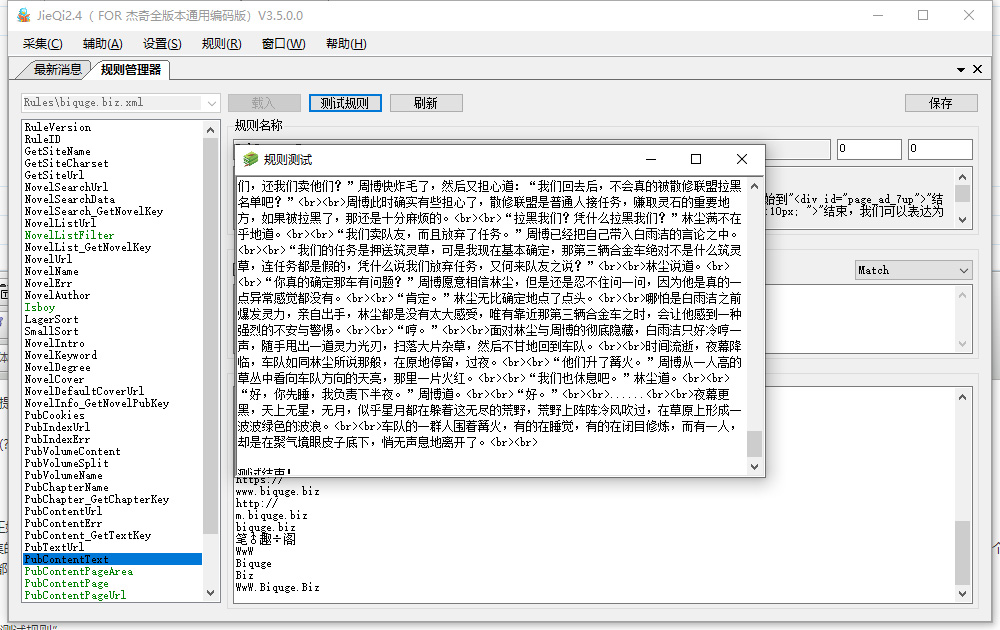
我们看到测试已经采集到文章内容信息,至此采集规则编写完成,预祝大家收录过百万,权重第一,收入倍增。








